What Is Deep Learning?
This is a really fascinating question! In this small overview post, I will try to answer it as clearly as possible. However, first things first. To start with, why did I decide to write about deep learning? It is simple: firstly, this topic is extremely interesting. Secondly, I couldn't get a satisfactory answer to a similar question several years ago. And even now, after so long, there is still no clear definition of what the “deep learning” actually stands for. Anyway, let’s ask Wikipedia and it will dryly tell you that deep learning “... is part of a broader family of machine learning methods”. OK. Then what is "machine learning"? Here, we have fallen into recursion, trying to dive deeper and deeper, following dozens of links and forgetting what we’ve been originally looking for… sounds sad, doesn't it?! Therefore, let’s try to take a look at the question from a different angle...
Artificial Intelligence
It is not an exaggeration to say that during recent years, the Internet has been flooded with the phrase "Artificial Intelligence" or simply, AI. I am sure that many of you have already dealt with it: headlines reporting that AI-powered system has won the world's best Go player, the computer learned to predict cancer better than the human, or that robots are quietly running through the forest...
All these are examples of computer programs that can perform some specific tasks defined by the programmers. Some definitions state that it is exactly what AI means. However, other, more exact definitions may say that AI is technology (built upon some specific hardware and software) that can (without human intervention) learn and perform creative functions, which are traditionally inherent in man, such as speech. But as of today, for instance, the system, that was designed to drive an autonomous car, cannot just start answering arbitrary questions. It seems that such tasks can only be done by very strong artificial intelligence like the human one. In general, in modern realities, one can argue for a long time about what artificial or even natural intelligence is. And, honestly speaking, clarifying this broad term is of no particular practical use, and although this topic is incredibly interesting, today it is not about that at all. Having started this conversation from AI, I wanted to emphasize that the question of artificial intelligence has been at the origin of modern deep learning and its most widely known technology: artificial neural networks, which is why it would be better to start with the history.
The Beginning of Artificial Neural Networks
For an overwhelming number of people, the concept of intelligence, whether or not artificial, is directly associated with the brain. It is not a secret, that this extremely important organ makes us human, endowing us with the special gift to think and realize ourselves as living and independent1 beings. This is why the brain has always been a subject of scientific research. The study of how brain cells - neurons - work, inspired two scientists Warren S. McCulloch and Walter Pitts to research, thanks to which, in the midst of World War II in 1943, their famous article introduced the concept of an artificial neural network (or NN). Such an artificial network was implemented using the connection of many elementary logical units or so-called artificial neurons. An artificial neuron behaves as a simplified version of its live analogue:
In 1950, Alan Turing, - the famous English computer scientist and mathematician - published a paper "Computing Machinery and Intelligence" in the philosophical journal "Mind". Turing described a test, where the computer must successfully impersonate a person in a written dialog between the judge-person, this computer and the third person. In other words, the goal itself was to determine whether the machine can think. This famous test marked the beginning of a discussion about the skills that a computer must master in order to behave like a person. This contributed to the fact that soon, in 1956, in a workshop at Dartmouth, the term AI would appear and its main tasks would be formulated.
Only one year later, in 1957, the young outstanding cognitive systems researcher at Cornell Aeronautical Laboratory, Frank Rosenblatt, developed an algorithm called "the perceptron". This algorithm was the first version of a single-layer feedforward neural network designed to independently study how to recognize handwritten letters. As such, the first steps were taken to teach the computer to see.
Unfortunately, single-layer perceptrons turned out to be ineffective in solving more complex problems with more data as well as classes to be classified. In addition, due to the lack of powerful computing resources, researchers did not even have the opportunity to appreciate the potential of this discovery, because the training procedure of even a simple network took a tremendous amount of time. These two main factors became crucial, and, the excessive optimism thriving in the academic and technical community ultimately frustrated experts as a result which of most NN research projects were suspended for several decades to come. Nevertheless, it was the perceptron that formed the basis of the technologies that help people today order coffee from Starbucks via smartphones, using a virtual assistant, or choose an interesting movie for Friday evening through Netflix.
Machine Learning
It should be noted that in parallel with the development of neural networks, many other research directions in the field of classification, regression, and clustering of data have evolved. In addition to neural networks, other widely known and useful algorithms have been developed, such as Support Vector Machine, k-Means Clustering, k-Nearest Neighbors or Principal Component Analysis. All these approaches, - including, of course, NNs themselves as well as the theoretical background behind them - soon began to be grouped by a common term: machine learning. In a sense, although the name speaks for itself, I would like to give a definition, which, in my opinion, is most capacious:
Machine learning is a field of computer science that studies how computer programs learn to perform certain strictly defined tasks.
The word "learn" in this context, in general, means that such algorithms are being programmed (hence, tasks are "strictly defined") to automatically process and understand the data they work with. In other words, they are trained on the data to do something specific without being explicitly programmed. Let's talk a little about it.
The Training
It is necessary to train NNs to make them capable of performing classification tasks. Therefore, in order to understand how it is done, it would be great to begin by taking a look at how the simplest network is arranged, at least superficially2.
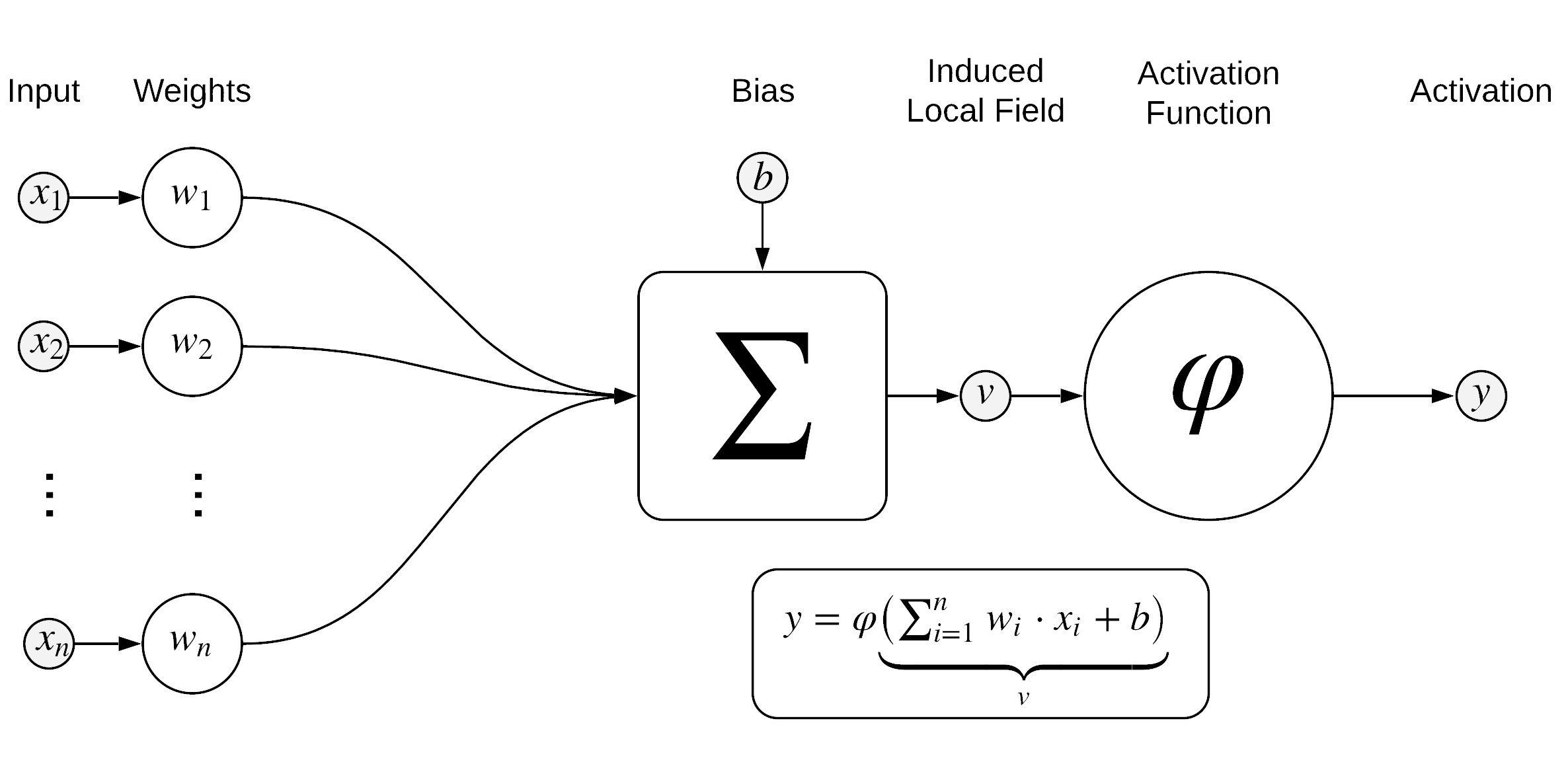
The aforementioned perceptron, or a feedforward NN, in other words, like any other kind of neural networks (yes, there are a lot of them, in fact, but we'll talk about it a little later on), from the mathematical point of view, is a regular multivariable function3 \(\overline{Y}\). This function processes some input \(\overline{X}\) and depends on the set of weights \(\lbrace \textbf{W} \rbrace\) of the connections between artificial neurons making it, so \(\overline{Y} = f_{\lbrace \textbf{W} \rbrace}(\overline{X})\).
We may take a look at this formal approach from a different angle. In this case, we can imagine a neural network as a set of interconnected artificial neurons (circles in the figure), which, like the brain, pass signals through themselves while interplaying. In a feedforward NN depicted below, these signals pass from the so-called input layer through the hidden layers (in the figure, there's only one hidden layer, highlighted in yellow) up to the uppermost, output layer. Under the signals and network weights (arrows in the figure), in most cases, the real numbers are meant.
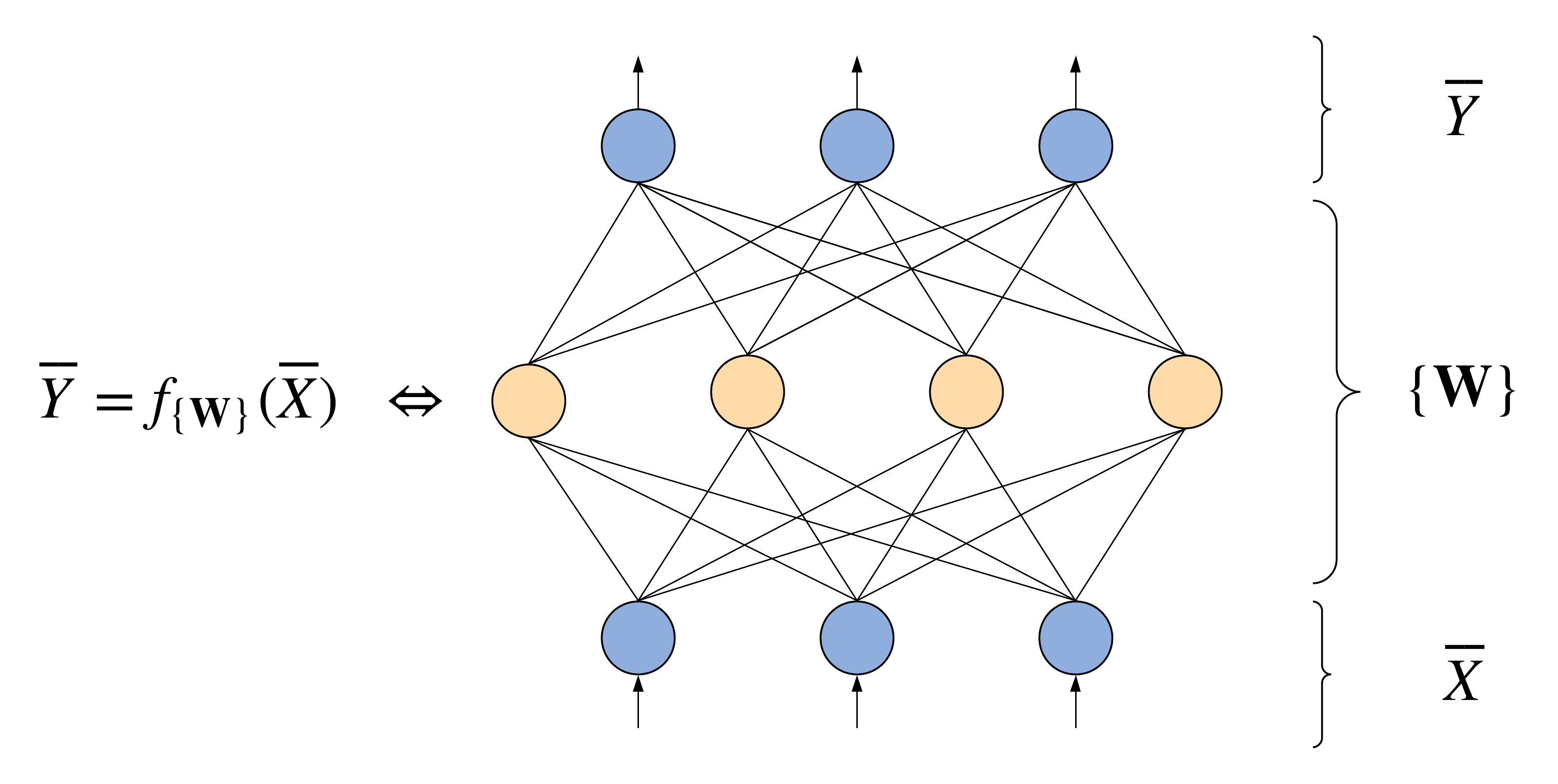
During classification, a network can make a mistake, at least because the network weights are usually initialized randomly. So, these weights are working as parameters regulating the output signals, which is their only purpose. And, as you have probably already guessed, all that is needed in order to force the neural network to produce the correct signals while processing specific data is to somehow adjust the weights. These weights can be obviously configured manually if you have only a few neurons in the network, but what if there are several million neurons? So the problem is, how to do it? Let's go back to history.
Several decades after the perceptron invention, thanks to a series of works in the early and mid-80s, the backpropagation algorithm was developed. This algorithm was just an automated approach of searching specific values of the network weights, which were making it produce output signals as close to the desired ones as possible. The search for these weights occurs during the processing of previously prepared data, which is usually called the training data. This is why the process of neural network weights adjustment for brevity is simply called "the training".
Thus, having some training data, after running the backpropagation procedure for some time if all the parameters and settings were selected correctly, you will get a network that can classify previously unknown data with certain accuracy. This ability is the most valuable property of neural networks, which is often called "the generalization" ability. To understand why this occurs this way, it is useful to draw an analogy with a student studying mathematics. The student should probably remember how to solve certain problems that were given in the lectures. However, the most important thing is how, during the exam, this student will be able to apply this knowledge to solve a completely new task. Similarly, with NNs, - the practical "usefulness" appears only when the generalization ability of a particular architecture is sufficiently high.
In summary of this section, I want to say that neural networks are just an abstract representation of some mathematical model that can be algorithmically tuned to produce specific output. Thus, generally speaking, the task of machine learning is to develop architectures and training approaches, that will allow the achievement of maximum possible generalization ability. So this is just programming and math. There is no magic. This is an essential detail worth paying attention to. Let's take a closer look at some important types of architectures.
Convolutional Neural Networks
Last quarter of the twentieth century, computational technologies have been developed at an incredibly rapid pace — the first personal computers with operating systems appeared, equipped with multi-megahertz central processors. Some of those computers were even equipped with the graphics processing units designed specifically for parallel processing of the (at that time, only graphic) data. All this rapid progress, both in computer science and in computational technologies, did not take long to wait. An incredibly important event took place: a real revolution in technology! Inspired by an idea of weights sharing introduced in 1986 by David Rumelhart, Geoffrey Hinton, and Ronald Williams in their article "Learning representations by back-propagating errors", after several years of continuous development4, researchers from AT&T Bell Laboratories led by Yann LeCun suggested a new image-processing NN architecture called "convolutional neural network" (or simply CNN). This architecture became the most advanced technology for image classification, and it remains so to this day.
The key feature of CNN is that it passes information through the special hierarchical layers5, where each layer performs its specific task:
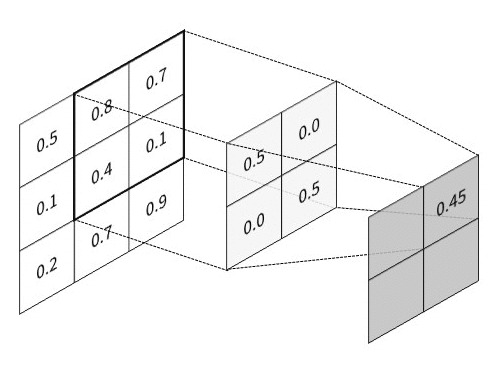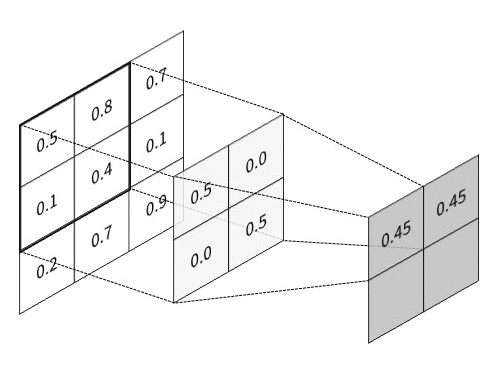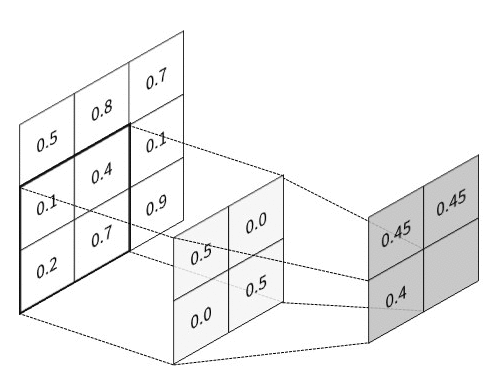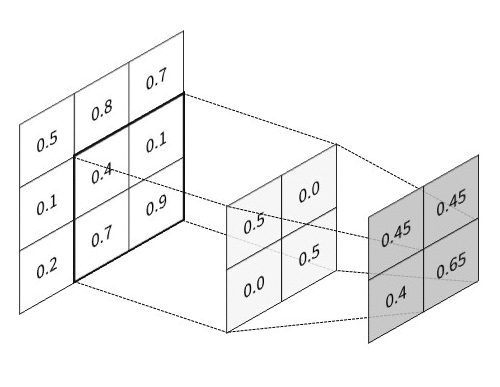
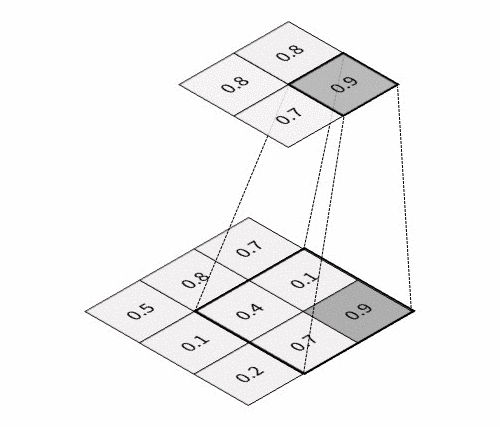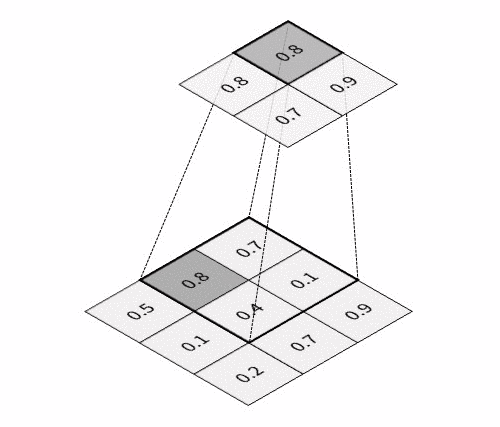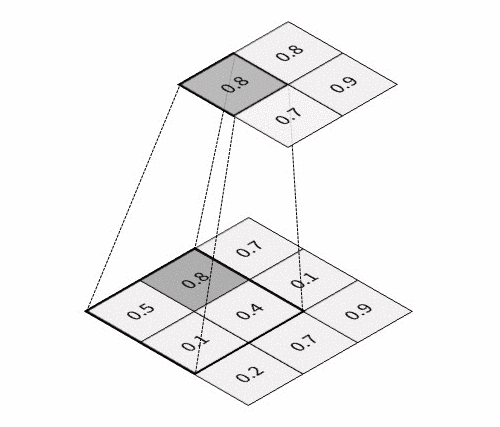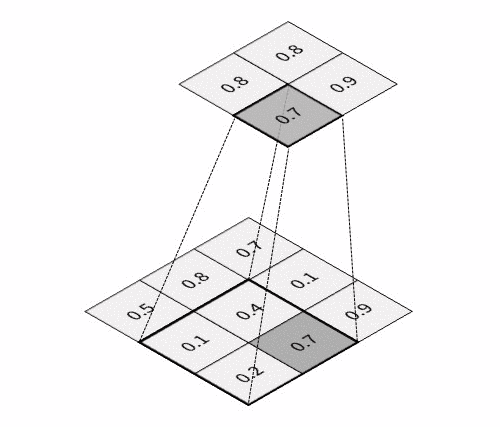
All these layers are usually combined into many consecutive cascades of convolution-then-pooling pairs, which finally make a pretty large architecture. And besides, these convolutional architectures, despite having much fewer trainable parameters, quite often significantly outperform feedforward NNs in almost all types of image classification tasks. Given below is a simple example of a CNN architecture that can be used for the classification of handwritten digits from the MNIST database:
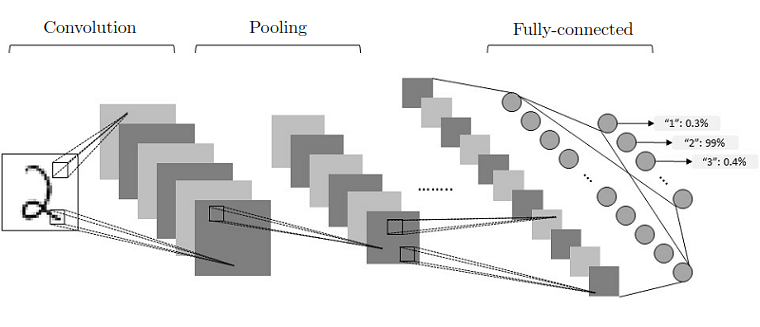
During CNN evolution, architectures were getting more and more deep. For example, some of them, like VGGNet with 16 layers, even won the famous ILSVRC contest in 2014. Today, CNNs with more than 100 (!) layers, are used to achieve state-of-the-art performance. In addition, it's impossible not to note that nowadays, CNNs are the basis of computer vision algorithms used in production. For example, modern self-driving cars use CNNs to look at the world, and thanks to it, they can navigate on roads.
In conclusion of this section, I want to say that we are now pretty close to the point, where we can finally formulate what deep learning actually is. But before doing that, let's sum up the intermediate results: it is because of the number of layers in such neural networks that they were named "deep", hence the name deep learning. Now, let's talk a little bit about another kind of neural networks, without which today, it would be impossible to imagine deep learning.
Recurrent Neural Networks
So far, we have been talking about architectures that are able to process data only in a single element at a time. For example, a neural network trained to classify images cannot process video directly. Alternatively, as another example, you say something to a virtual assistant and it somehow understands you. How is this neural network made? All this is possible thanks to the so-called recurrent neural networks (RNNs), or specific networks for processing sequences6. When processing the current sequence element \(x_{t}\), such NNs use information obtained after processing the previous elements of the sequence: \(x_{t-1}, x_{t-2},\ldots\) and hence the name, "recurrent".

RNNs, in a sense, are capable of "memorizing" what they've just seen, thereby making the sequence processing much more efficient. It is important to note that from the algorithmic point of view, operation of the perceptron and the way it learns, is very similar to what happens with recurrent networks. The main differences are that firstly, the recurrent neurons are a bit more complicated and, secondly, instead of the pairs "expected input" - "expected output", the training process is modified to work with pairs of the "expected input sequence" - "expected output sequence" type. Usually, at the top of RNN, identical to convolutional networks, a few fully connected layers are used for the final classification. This makes convolutional and recurrent networks very similar in some way, but we will come back to this a little later.
Some types of recurrent neural networks are even able to memorize enough to process natural language sentences and translate them. For example, from English to French. Unfortunately, simple recurrent networks are not suitable for such a task. But the situation changed dramatically, thanks to a breakthrough made by two computer scientists, Sepp Hochreiter and Jürgen Schmidhuber. In 1997, their article, entitled "Long Short Term Memory" was published. This article described a new, advanced RNN architecture (LSTM) that became a significant event in the development of NNs and machine learning as a whole. The main advantage of LSTM neurons - usually called cells - over ordinary recurrent neurons, is their ability to learn what needs to be remembered and what needs to be "forgotten" during signal processing. In fact, LSTMs impacted the entire industry, having made speech recognition, machine translation, and other AI systems worldwide accessible.
In the example about talking to a virtual assistant, your speech is continuously recorded by a smartphone. It splits the sound signal by short time frames, which are further processed and directed right into the trained RNN, predicting the most possible sound or letter you've just pronounced within this frame. The sequence of predicted letters and sounds is thus transformed into the text you may see on the screen.
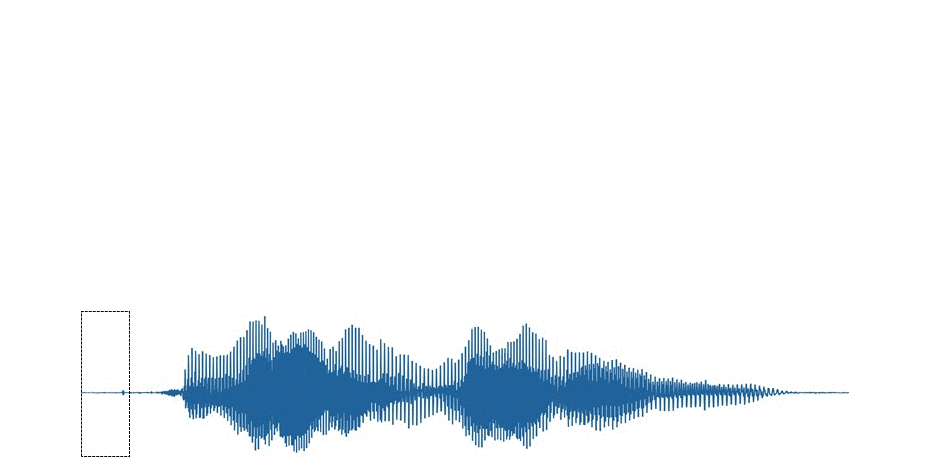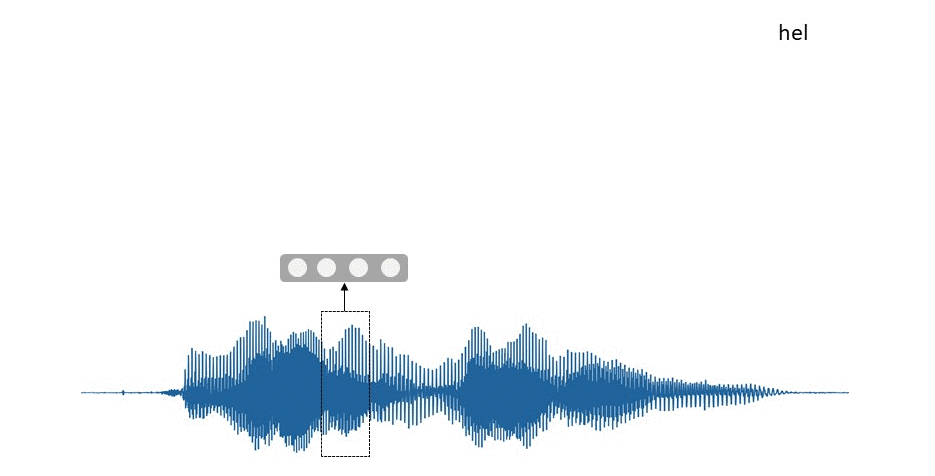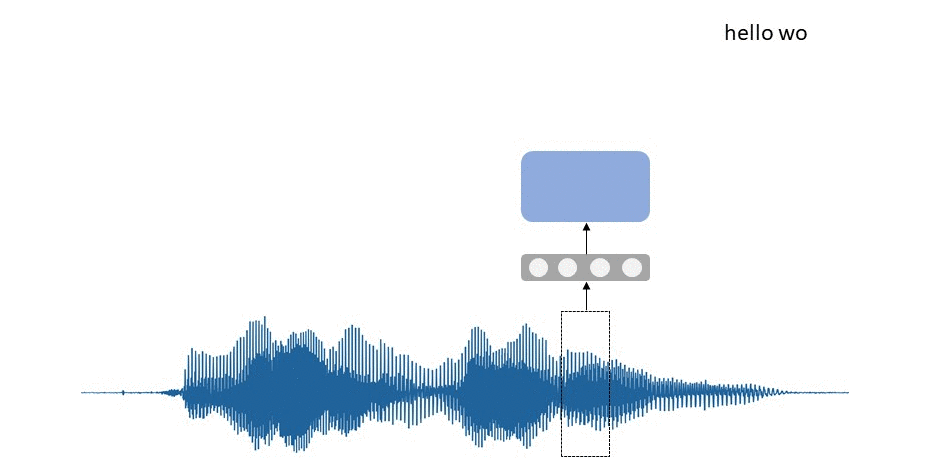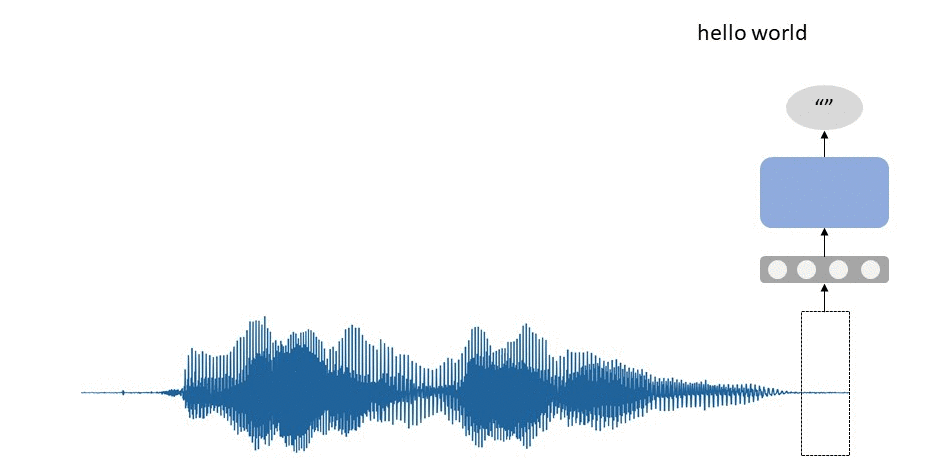
Some RNNs might be really large and deep, i.e., similar to perceptrons or CNNs, recurrent networks can have multiple hidden layers. Some of them may even be bidirectional, in that, they process the sequences in two directions simultaneously, like BERT. This approach allows slight improvement in the performance. Exactly as in the case for other architectures, increasing the size of a network generally slows down its training, and at the same time, increases its ability to memorize more and better.
Advanced Architectures
Nowadays, neural networks are not just used separately. Very often, different architectures are combined into sophisticated systems to solve very difficult tasks, for example, generating descriptions for images, leveraging LSTMs and CNNs at once, as described in this article.
Architectures capable of recognizing various objects in images or even tracking them in real time have particular practical value. See this, this or this article for more details.

NNs can also be used for semi-supervised and unsupervised tasks. A great example is generative adversarial networks or GANs (take a look at this and this article to dive deeper). In this approach, two neural networks, combined into a single system, train each other: one network - also known as the generator - generates fake data, and the second network - the discriminator - learns to distinguish fake data from real data. After such training, the generator will generate samples that may be very similar to the real ones. Perhaps, you have already seen some of the extremely realistic faces created by a GAN that was trained on the images with people's faces. This seemingly funny way of applying deep learning in real life can be very useful for science. As an example, see this article describing the usage of GANs for understanding the evolution of galaxies.
I don’t know why, but people often forget about the wonderful application of neural networks: an autoencoder. Autoencoders have great potential as well as practical value for image processing. For example, using pairs of "clean-noisy" images, it is possible to teach the network to remove noise from images (see this article to know how it works in detail). Similarly, autoencoders can be used, for example, to remove some objects from images or even to color a black and white movie. It is really interesting, and maybe I will soon write about autoencoders in a separate post.
Of course, it is impossible to ignore NNs' application for natural language understanding (NLU). Today, this area is also booming due to the fact that people are talking to various voice interfaces using their smartphones. In addition to the regular LSTM networks and their modifications, progress has generated new architectures. A new technology, called the attention mechanism, has become indispensable in all modern NN-based NLU systems. This algorithm allows neural networks to automatically determine the most important parts of the sequences to be processed, thereby helping the networks to perform better. Most of today's state-of-the art NLU tasks - such as text classification, question answering, and translation - use the attention mechanism in various forms. To learn more about it, pay attention to this article.
Deep Learning
Somehow, quite imperceptibly, our conversation transmogrified into a discussion of various structures of neural networks. Well, today the term "deep learning" is, in some sense, directly associated with neural networks. Nevertheless, let's slow down a bit and finally try to formulate what deep learning is.
Consider convolutional and recurrent networks for a classification problem. Do you remember how we have been discussing that these two architectures are somewhat similar? We have discussed the addition of a fully connected layer on the top of both these neural network types. Accordingly, fully connected layers are mainly used to transform the internal representations formed by the networks into the probabilities, suggesting which particular class this or that processed example belongs to. Actually, that's the point. Such deep (i.e., with many layers) neural networks are able to "form an idea" of the data they are trained on. Moreover, they can do it effectively and independently. And it is not necessary to explicitly explain to them, during image processing, that cats have two pointy ears or that in text processing, it is common in English for questions to put the auxiliary verb first. Such architectures are designed to retrieve and interpret this kind of information on their own.
Another example: have you ever thought what actually makes a table - a table? It might be wooden, steel, or glass made. It has four legs in most of the cases. But how to teach a computer to deal with it directly? How to explain to it that some object in an image is a table? In fact, there is simply no way to do that. We, as people, understand this subconsciously, without even having to think about it. The training of a deep neural network takes place in a similar manner. No one and anywhere explicitly says that this is the table or its legs. No. There are just thousands of labeled images. It is the task of the networks to process these images and learn how to understand whether there is a table in there. Thus, the weights of a neural network during the training are configured to evaluate the features of an image effectively. These weights form the so-called representations which are used to make correct predictions7.
So, definitely, deep learning is a part of machine learning. And according to the above, in contrast to the approach when a specialized algorithm is explicitly trained to perform some specific task, deep learning algorithms are capable of learning data patterns and specific features which are mostly hidden. So there is a brief and general definition that I stand by:
Deep learning studies algorithms (mostly multilayer neural networks), which can learn various data representations.
Here, I would also like to point out that deep learning has gained popularity only in recent years, because only modern training approaches and computational technologies have made deep learning useful in practice. More specifically, the time for training a deep neural network has become much more adequate. However, in fairness, some large networks are still trained for many days even on distributed systems.
Isn't That Wonderful?
At the very beginning of our conversation, I mentioned that AI is developing extremely rapidly and there are more and more useful applications for it, which is definitely great. However, is everything as wonderful as it seems at first glance? We will not dive deep into this difficult question today, since I just want you, as a reader, to have an idea about all aspects: positive and negative. I would like to point out just a few basic problems.
Indeed, as it usually happens, what works fine in theory is sometimes not easy to put into practice.
What's Next?
It is important to note that modern deep learning is not only neural networks being used to classify some data. There are many other essential research directions which aren't less important. I would like to highlight only several major directions of current research:
Thus, in the nearest future, we, of course, will not see robots making some really funny jokes by themselves, but will definitely see that AI technologies will be introduced into different areas of our lives more rapidly and deeply.
Epilogue
The post turned out not as small as I had initially assumed. Indeed, the topic of deep learning is so extensive that even a book is not enough to embrace it. Nonetheless, I hope that after our conversation today, you have got a general idea of what deep learning is and that there is no magic behind it at all. Thanks for reading this.
References
Here is a small list of sources, the reading of which inspired me to write this post:
Notes
- Take a look at the book “The Domesticated Brain” by Bruce M. Hood, if you’re interested in the question why it is so.↩
- See this post for details.↩
- Check out this article to remind yourself what it is.↩
- However, the idea originated in 1989 and proposed in this article.↩
- See this marvelous guide explaining CNNs in more detail.↩
- This question deserves a separate discussion and I will definitely try to write a separate post about it. But as of now, we will touch it only superficially. ↩
- For more examples, I do recommend you take a look at this wonderful article talking about CNNs and how they build their internal representations of the data they were trained on. ↩
- To know more about it see this post.↩
- I suggest you to read Philip Piekniewski's objective assessment of the current state of affairs in the field of deep learning.↩
- See this article to know why this future still far away.↩